|
I am an AI/ML researcher at Mobileye, working on ML for autonomous vehicles. I did my Ph.D. at Weizmann Institute of Science, advised by Prof. Michal Irani, where I worked on machine learning and computer vision, and more specifically, Generative AI and understanding memorization in neural networks. I did my Msc. in theoretical astrophysics, advised by Prof. Boaz Katz, and worked with Prof. Yaron Lipman on Geometric Deep Learning. I received my BSc. in computer science and physics from the Technion (Lapidim excellence program alumnus) |

|
|
|
|
|
Yakir Oz, Gilad Yehudai, Gal Vardi, Itai Antebi, Michal Irani, Niv Haim SaTML 2026
|
|
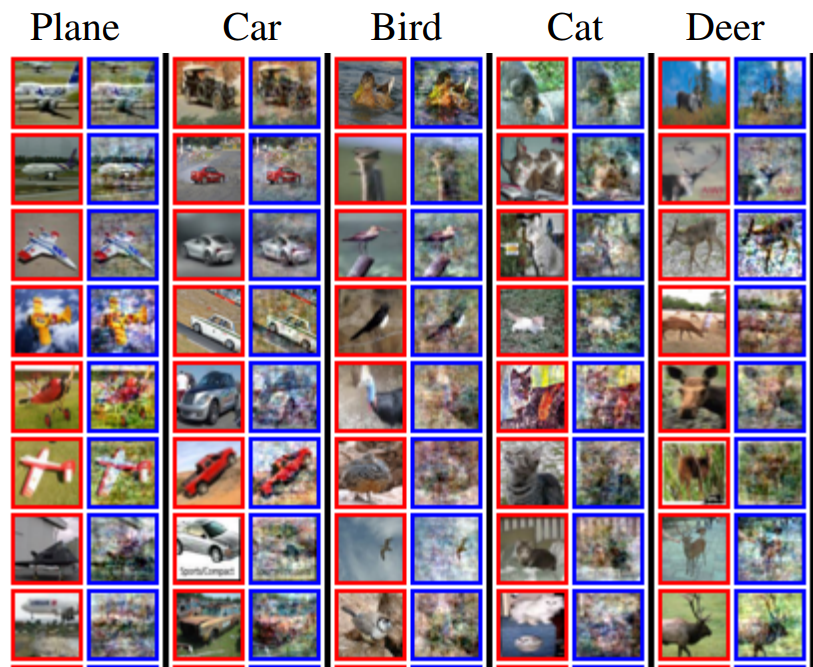
Gon Buzaglo*, Niv Haim*, Gilad Yehudai, Gal Vardi, Yakir Oz, Yaniv Nikankin, Michal Irani NeurIPS 2023
BibTeX /
ArXiv /
Code /
Video
Training set reconstruction from multiclass classifiers and models trained with regression loss with some inriguing observations on the implications of weight decay on reconstructability. (Earlier version appeared in ICLR Workshop on Trustworthy ML, 2023) |
|
|
Yaniv Nikankin*, Niv Haim*, Michal Irani ICML 2023
BibTeX /
ArXiv /
Code /
Project Page
Diffusion models can be trained on a single image or video, giving rise to diverse video generation and extrapolation. |
|
|
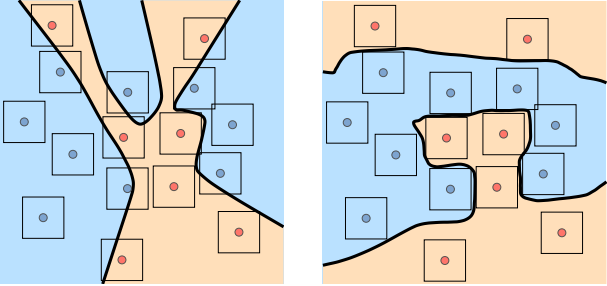
Niv Haim*, Gal Vardi*, Gilad Yehudai*, Ohad Shamir, Michal Irani NeurIPS 2022 ORAL
BibTeX /
ArXiv /
Code /
Project Page /
Video
We show that a large portion of the training data can be reconstructed from the parameters of trained MLP binary classifiers. Our method stems from theoretical results about the implicit bias of neural networks trained with gradient descent |
|
|
Niv Haim*, Ben Finestein*, Niv Granot, Assaf Shocher, Shai Bagon, Tali Dekel, Michal Irani ECCV 2022
BibTeX /
ArXiv /
Code /
Video /
Project Page
We generate diverse video samples from a single video using patch-based methods. Our results outperform single-video GANs in visual quality and are orders of magnitude faster to generate (Extended abstract appeared at AI For Content Creation Workshop @ CVPR, 2022) |

|
Assaf Shocher*, Ben Finestein*, Niv Haim*, Michal Irani Preprint, 2020 |

|
Amos Gropp, Lior Yariv, Niv Haim, Matan Atzmon, Yaron Lipman ICML 2020
|
|
Matan Atzmon, Niv Haim, Lior Yariv, Ofer Israelov, Haggai Maron, Yaron Lipman NeurIPS 2019
|

|
Niv Haim*, Nimrod Segol*, Heli Ben-Hamu, Haggai Maron, Yaron Lipman ICCV 2019
|
|
|
Niv Haim, Boaz Katz MNRAS 2018
|
|
|
|
Reconstructing Training Data from Trained Classifiers: Long Presentation at Microsoft Data Science Bond Short Presentation at Israeli Vision Day 2023 Introduction to Adversarial Examples: DL4CV2021 DL4CV2023 |
|
|
 Weizmann Institute Weizmann Institute of Science |
Blog Post: How to Give a Good Student Seminar Presentation
Deep Learning for Computer Vision [Winter 2021, Winter 2022] Advanced Topics in Computer Vision and Deep Learning [Spring 2020, Spring 2021, Spring 2022, Spring 2023] Deep Neural Networks - a Hands-On Challenge [Spring 2017] |
|
|
|
I play the violin [YouTube]
I sometimes write about my travels [blog] |
|
This website is based on Jon Barron's homepage template |